El ejemplo del resumen hash que has dado es demasiado corto (20 bits o alrededor de un millón de posibilidades), por lo que tendrías colisiones con demasiada frecuencia y, lo que es peor, cualquiera que haya descompilado tu programa podría producir las cadenas correctas (o , al menos, cadenas que son aceptables debido a las colisiones de hash) simplemente forzando bruscamente el posible espacio de entrada.
"Esa es una objeción tonta. Es solo un ejemplo ..." podría decir, pero realmente no lo es. He encontrado, y explotado, este tipo exacto de debilidad antes. Por ejemplo, había una aplicación móvil que usaba una función hash de 32 bits en las entradas del usuario para intentar ocultar qué entradas producirían qué salidas. Tardó menos de una hora en escribir y ejecutar un programa que forzó bruscamente el espacio de búsqueda y encontró entradas que se asignaban a cada resumen de hash que la aplicación estaba buscando.
En esencia, esto es muy parecido a tratar de almacenar contraseñas de forma segura. Definitivamente hay diferencias: las contraseñas rara vez son muy largas, mientras que las cadenas codificadas en un programa pueden serlo, y si realiza la prueba de igualdad de cadenas con frecuencia, no puede permitirse que sea tan lenta como una buena función de verificación de contraseña. ser - pero muchos de los mismos paralelos se mantienen. Utilice una función hash fuerte, no solo resistente a las colisiones y la reversión, sino también a una que no sea tan rápida como sea posible para forzar la fuerza bruta en todo el espacio de búsqueda. Para cadenas cortas, use sal para que las personas no puedan simplemente buscar el valor en una tabla de arco iris.
Ahora, en cuanto a la ofuscación real: esta técnica es una (de muchas) que la ofuscación puede usar. Por lo general, no es muy efectivo, especialmente cuando se implementa de manera débil (vea mi segundo párrafo), y tiene un impacto suficiente en el rendimiento que no se usa normalmente, excepto de manera selectiva en lugares donde la desaceleración no es un gran problema. La ofuscación en general es una no solución; en el mejor de los casos, ralentiza la ingeniería inversa lo suficiente para que, para cuando se complete el RE, la base de código sea lo suficientemente antigua, a nadie le importe, sin que se produzcan errores indebidos de rendimiento o lógica del programa. En la práctica, sin embargo, generalmente no es tan bueno.
{kind=link}
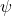{kind=link}
{kind=link}
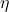{kind=link}
{kind=link}
{kind=link}